New features: Whole genome clustering and BaseSpace integration
Today we’re happy to announce two new features for all users on One Codex: whole genome clustering and integration with Illumina’s BaseSpace. The first opens the door to new types of analyses, while we hope the second will allow many to spend less time moving their data around and more time exploring it!
Whole (meta)genome clustering
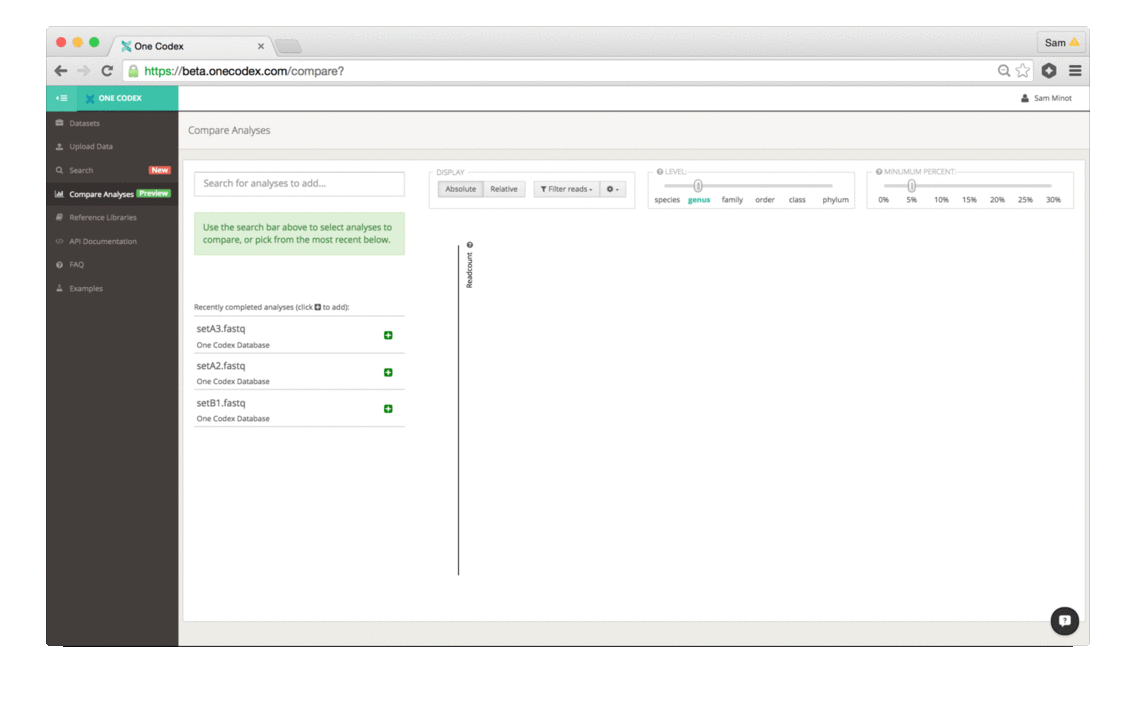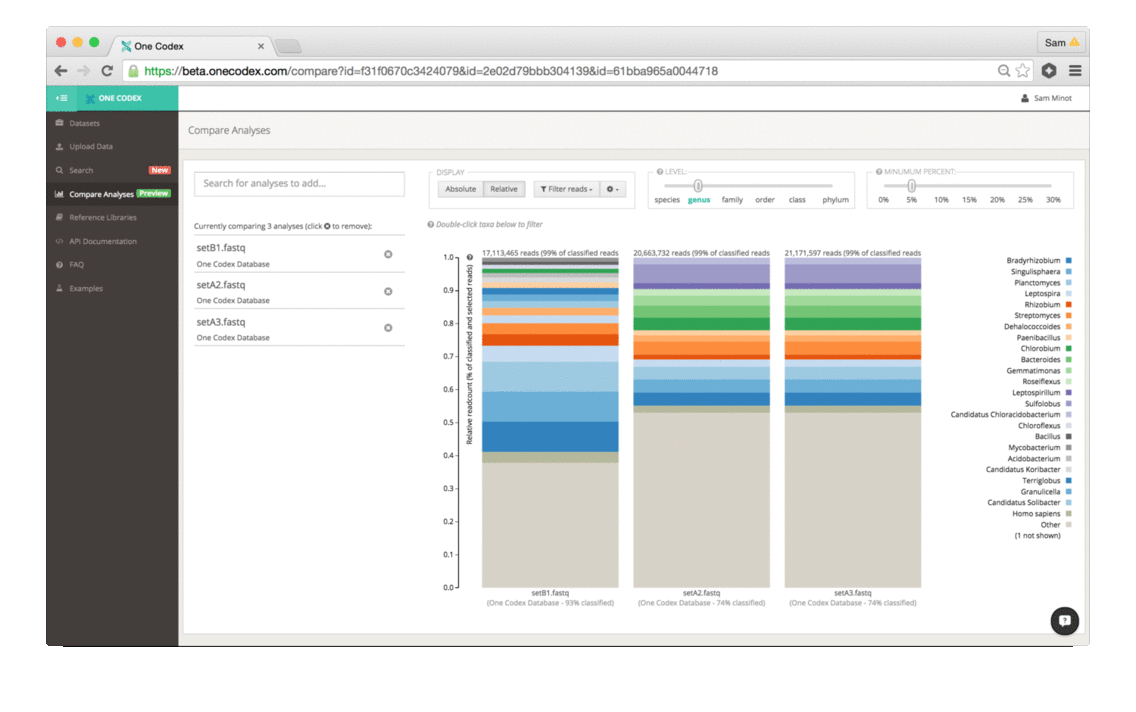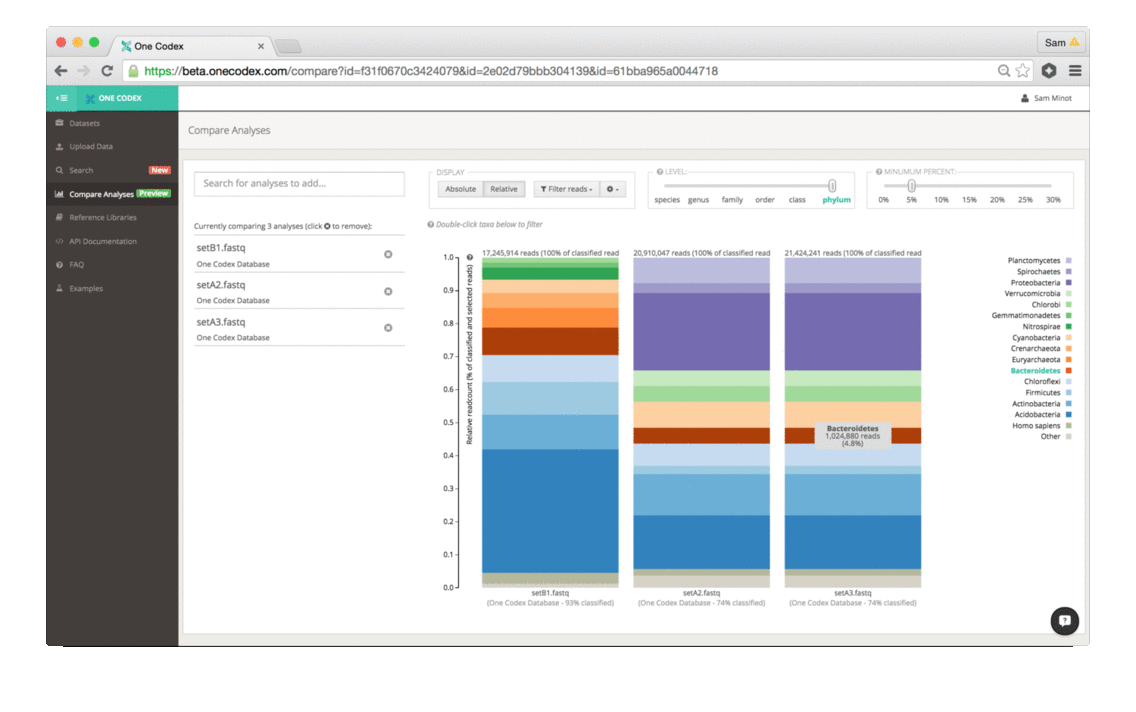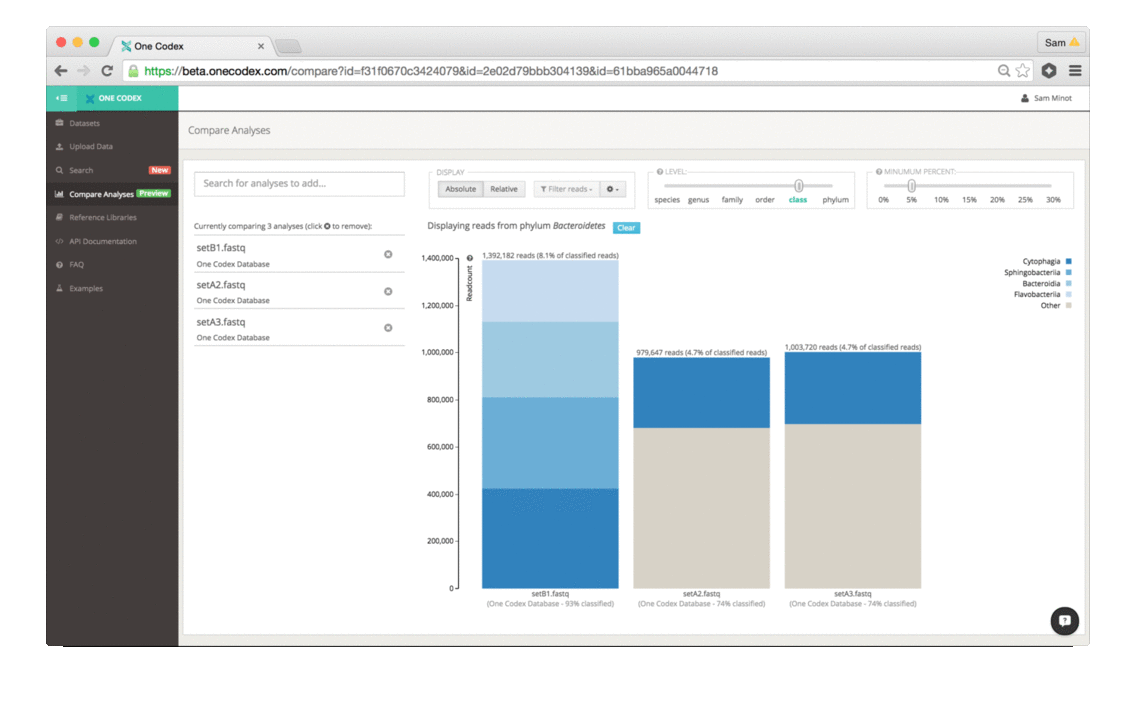
In addition to our previous sample comparison tool, we’re very excited to announce that One Codex now supports arbitrary, interactive exploration and clustering of your isolates and metagenomic samples. This cluster view (login/free registration required) enables rapid, reference-free exploration and comparison of NGS samples, often both highlighting expected similarities and revealing important inter-sample differences.