Announcing the Targeted Loci Database for 16S and other amplicon sequencing
Scientists that study the microbiome generally use two different methods to analyze samples – sequencing all of the DNA in a sample (whole genome sequencing) or targeting a specific marker gene (e.g., 16S, 18S, ITS). While whole genome sequencing (WGS) enables high-resolution taxonomic and functional characterization of microbiome samples, 16S sequencing is a cost effective technique for broad community surveys across large numbers of samples. Today, we’re excited to announce that One Codex is launching a powerful new tool for 16S and other amplicon sequencing – making high-quality, reference-based analysis of marker gene studies easier, faster, and more accessible.
The Targeted Loci Database
One Codex’s Targeted Loci Database is specifically designed for marker gene sequencing and built using the most common genes employed in microbial surveys, including 16S, 18S, and ITS. The Targeted Loci Database contains ~250,000 full length gene records that we’ve curated from across the known microbial world – bacteria, archaea, fungi, protists, algae, etc.
Analysis with the Targeted Loci Database provides:
- Highly accurate microbial identification from 16S, 18S, ITS, etc.
- Robust ecological characterization and more stable, accurate diversity metrics
- Completely reproducible analyses using a stable, versioned database
- Cross-sample comparison scaling to 1,000s of samples using the One Codex platform
More accurate, robust amplicon sequencing analysis
We analyzed a mock community used by Kopylova, et al. (2016) to compare One Codex’s Targeted Loci Database against the widely used tools QIIME1 and mothur.2
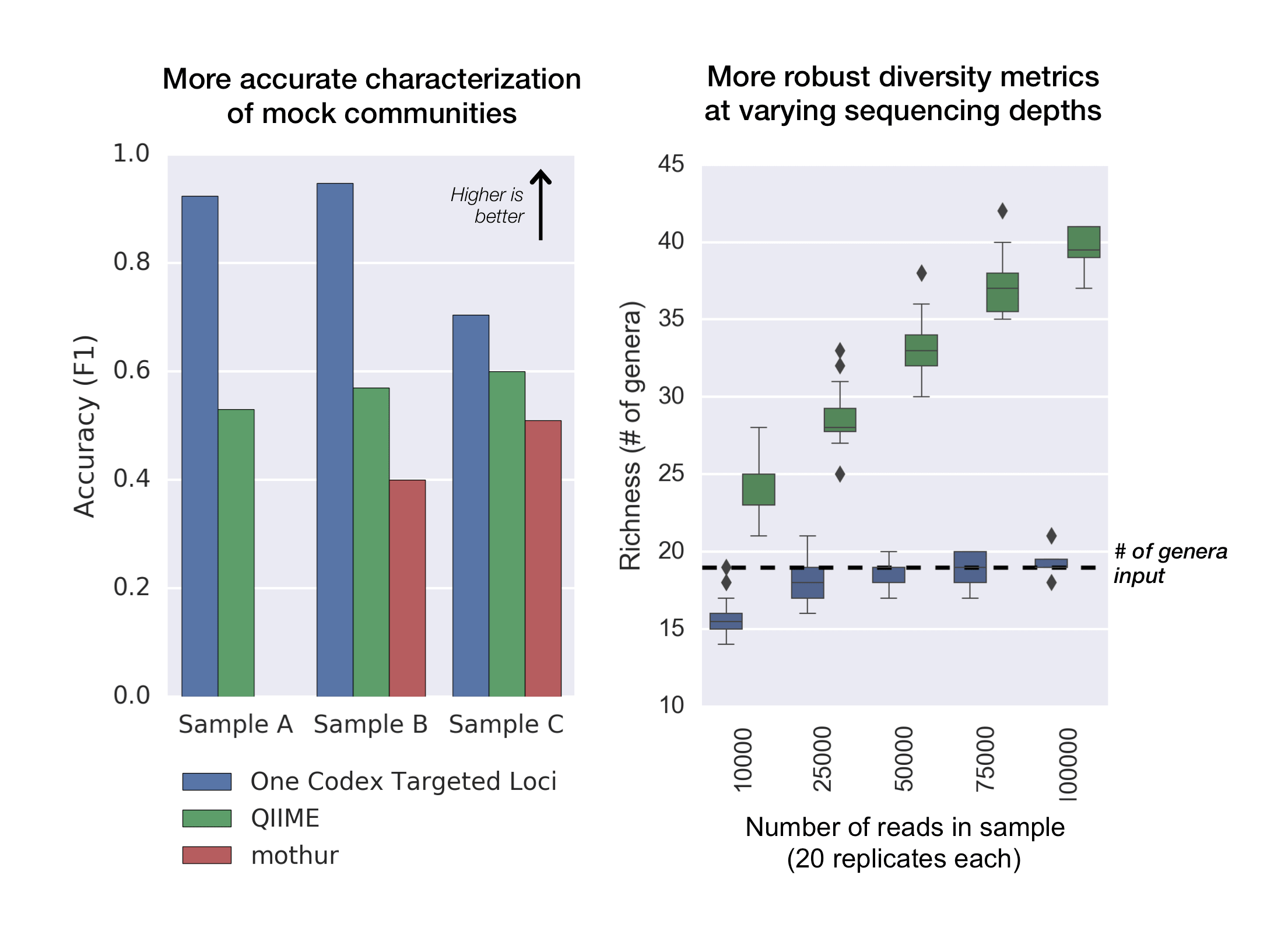
The left panel shows that the Targeted Loci Database provides more accurate results across all three of the mock communities from Kopylova, et al. The right panel shows improved community diversity metrics that are accurate and robust despite varied sequencing depth. More details on this analysis and the Targeted Loci Database’s development are available in our documentation.
An end to n+1 re-analyses
A common challenge with QIIME, mothur, and similar clustering-based analysis methods is the requirement to analyze samples in fixed batches. This often leads to the “n+1” sample problem, where the addition of a single sample requires re-analyzing an entire study. This also confounds meta- and other cross-study comparisons.
A key feature of One Codex is that samples are analyzed independently in a reference-based framework and analyses are strictly versioned. This allows rapid processing of samples as they come off the sequencer, instant sample comparison across large collections, and the ability to compare 16S and WGS data using a common reference framework (the NCBI taxonomy). All of these advantages enable faster, more flexible discovery across large amplicon sequencing studies.
Using the Targeted Loci Database
To run the Targeted Loci Database on your samples in One Codex, go to the Run Analysis page, select your samples of interest using the menu on the left, and then click the Run button for the Targeted Loci Database on the right. This analysis may be run on any sample uploaded to One Codex at no additional cost. More details can be found in our documentation.
Questions? Comments?
As always, please feel free to drop us a note if you have any questions, feedback, or would like to discuss a project.
– Sam Minot, Ph.D.
1 QIIME was run with default settings, which include pick_open_reference_otus.py (v1.9.1), uclust for clustering and gg_13_8_otus/rep_set/97_otus.fasta as the default reference database.
2 Mothur was run using “furthest neighbor” clustering (Kopylova, et al., 2016), and that analysis pre-dated the release of OptiClust as the default option for clustering. The authors only presented mothur results for two of the three available test datasets.
